谈谈JS运行
学习web前端多年,总该有点总结。今天想来谈谈,一段js代码被浏览器读取后,接下来是怎么运行的。
想一想:浏览器不过是运行在系统上的一个程序,js代码有是通过浏览器来操作系统的;shell也是一个程序,在shell上输入的命令会通过shell程序最终于系统进行交互;desktop也是一个程序,通过转化用户的输入、点击等最终于系统进行交互。
起初在浏览器眼里js不过是一串普通字符串,像一块原铁还要经过锻造打磨才能变成利剑;这个锻造打磨分成两个阶段,即先编译后执行
一、编译阶段
编译阶段主要有3个步骤
1. 词法分析
将代码字符串分解成一个个独立的、具有意义的词法单元(token),例如var a = 1;会被分解成var、a、=、1、;等词法单元。 Tokens如下:
[
{
"type": "Keyword",
"value": "var"
},
{
"type": "Identifier",
"value": "answer"
},
{
"type": "Punctuator",
"value": "="
},
{
"type": "Numeric",
"value": "1"
},
{
"type": "Punctuator",
"value": ";"
}
]
2. 语法分析
对词法分析生成的tokens进行语法检查,并构建一个抽象语法树(Abstract Syntax Tree, AST)。这个过程会验证代码是否符合 JavaScript 的语法规则,并建立起代码的结构性。以便于理解和执行
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "answer"
},
"init": {
"type": "Literal",
"value": 1,
"raw": "1"
}
}
],
"kind": "var"
}
],
"sourceType": "script"
}
3. 生成可执行代码
在 AST 的基础上,生成可以执行的代码,需要通过某种方法将 var a = 1; 的 AST 转化为一组机器指令,用来创建 a 的变量(包括分配内存),并将值存储在 a 中。
4. 创建执行上下文
函数在执行前,还会生成对应的执行上下文(可以看成是存储对应函数变量值的对象),记录了this绑定关系、词法环境和变量环境。
对应全局代码的叫全局执行上下文,函数代码的叫函数执行上下文,Eval函数代码的叫Eval函数执行上下文。
1. this绑定
此时还没有确定this的绑定关系
2. 创建变量环境
变量环境是一个对象,保存var变量和function函数声明,此时var变量会被赋值为undefined,函数变量会被赋值为函数体,所以函数能够在声明前就被调用。
3. 创建词法环境
词法环境是保存let和const变量的,与变量环境不同,它是栈结构,这很关键,块级作用域源于此;在函数执行前,词法环境内是空的,所以在let和const声明前调用会报错。
4. outer指针
值得注意的是,在编译阶段就确定了outer指针的指向,它会指向外层函数声明处的执行上下文,所以说作用域链是在编译阶段确定更函数的声明的物理位置有关。
二、执行阶段
仔细观察发现,js代码的执行分为全局代码和函数代码,但全局代码其实可以看成一个像java或C语言的入口main函数。
1. 执行栈
函数执行时会将对应的执行上下文压入执行栈;全局代码也可以看成一个全局函数,当js引擎开始执行第一行 JavaScript 代码时,它会创建一个全局执行上下文然后将它压到执行栈中,每当引擎遇到一个函数调用,它会为该函数创建一个新的执行上下文并压入栈的顶部。
引擎会执行那些执行上下文位于栈顶的函数当该函数执行结束时,执行上下文从栈中弹出,控制流程到达当前栈中的下一个上下文。
当函数执行时,对应的执行上下文会被压入执行栈,函数执行过程也会不断更新对应的执行上下文
1. this绑定
在函数执行上下文中,this 的值取决于该函数是如何被调用的:
通过对象方法调用函数,this 指向调用的对象
声明函数后使用函数名称普通调用,this 指向全局对象,严格模式下 this 值是 undefined
使用 new 方式调用函数,this 指向新创建的对象
使用 call、apply、bind 方式调用函数,会改变 this 的值,指向传入的第一个参数
2. 更新变量环境
根据实参更新变量值,执行过程更新变量值。
3. 更新词法环境
词法环境是保存let和const变量的,与变量环境不同,它是栈结构,这很关键,块级作用域源于此;在函数执行前,词法环境内是空的,所以在let和const声明前调用会报错。
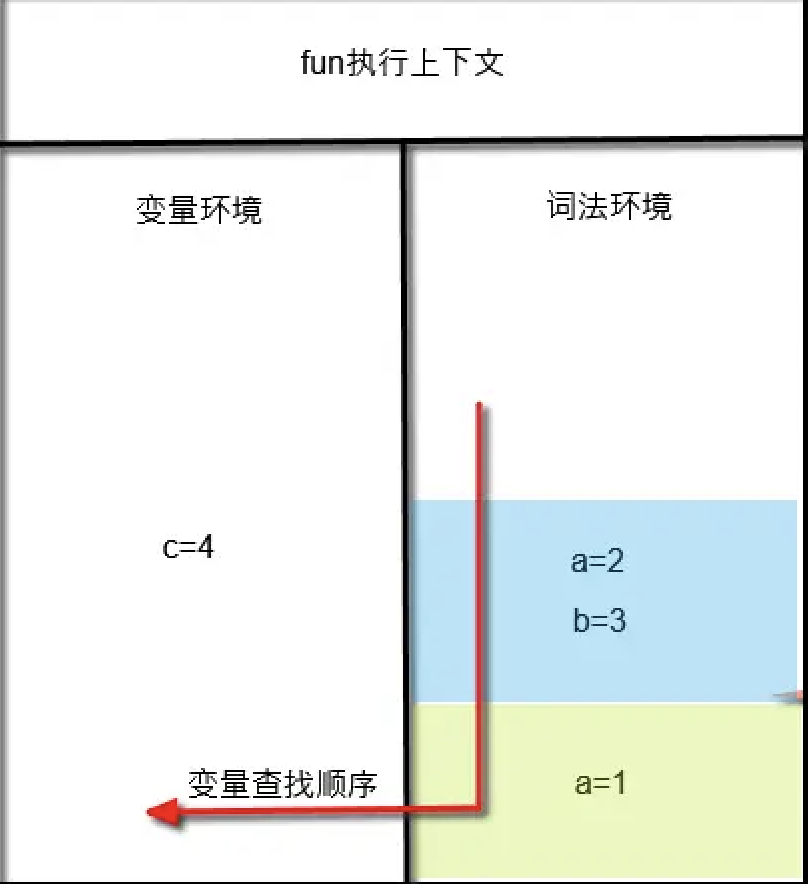
栈底是函数最外层let和const变量环境,函数执行到块级作用域处,就会把块级作用域内的let和const变量环境压入栈中,那么当调用let变量时,就会在这个栈中从上往下查找。因为是函数执行到块级代码处,才会将对应的变量环境压入栈,当块级代码执行完后,对应的变量环境又会从栈中弹出,所以let、const声明的代码不具有声明提升能力。
块级作用域理解:
function fun()
{
var c=4
let a = 1
{
let a = 2
let b = 3
console.log(a)
console.log(b)
}
console.log(a)
console.log(b)
}
fun()
 思考下面不同:
思考下面不同:
for(var i=0;i<10;i++){
i++
setTimeout(()=>{
console.log(i)
})
}
for(let i=0;i<10;i++){
i++
setTimeout(()=>{
console.log(i)
})
}
2. 作用域链
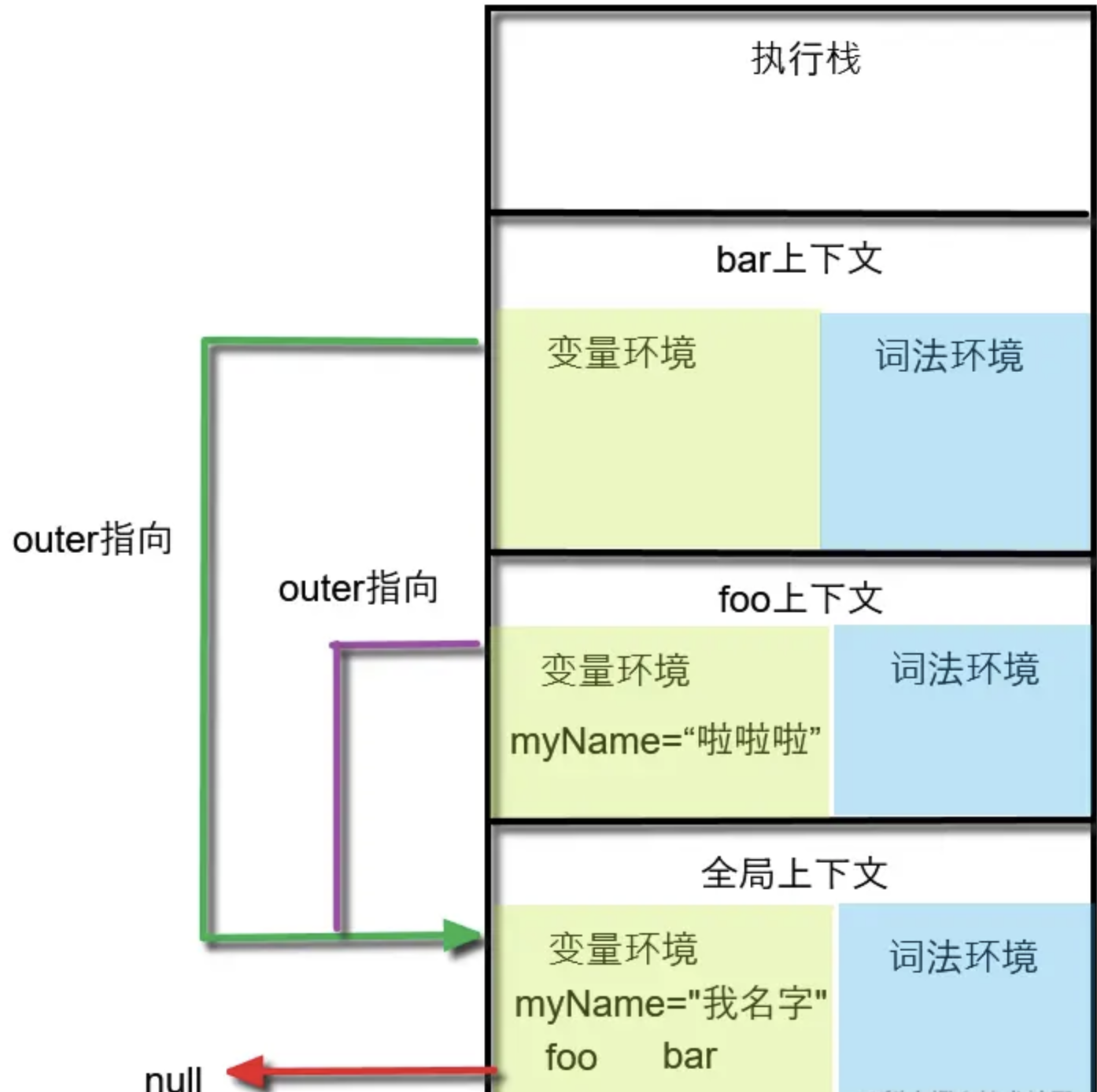
在执行上下文内部,变量访问总是从词法环境的栈顶开始到栈底,然后到变量环境。在执行上下文之间,即执行栈内,是通过outer变量或叫指针(每个执行上下文都会创建一个outer变量用来指向下一个作用域)访问下一级上下文(注意是下一级不是下一层),直到全局执行上下文结束。这个变量访问顺序就是作用域链。
值得注意的是:这里的outer指针访问下一级执行上下文,并不是下一层上下文,而是outer变量指向的下一个上下文,outer的指向编译阶段确定好的规则,指向它函数声明处外层的函数,所以一直说作用域链基于静态作用域。
function bar(){
console.log(name)//我名字
}
function foo(){
var name='hello'
bar()
}
var name='wison'
foo()
3. 闭包
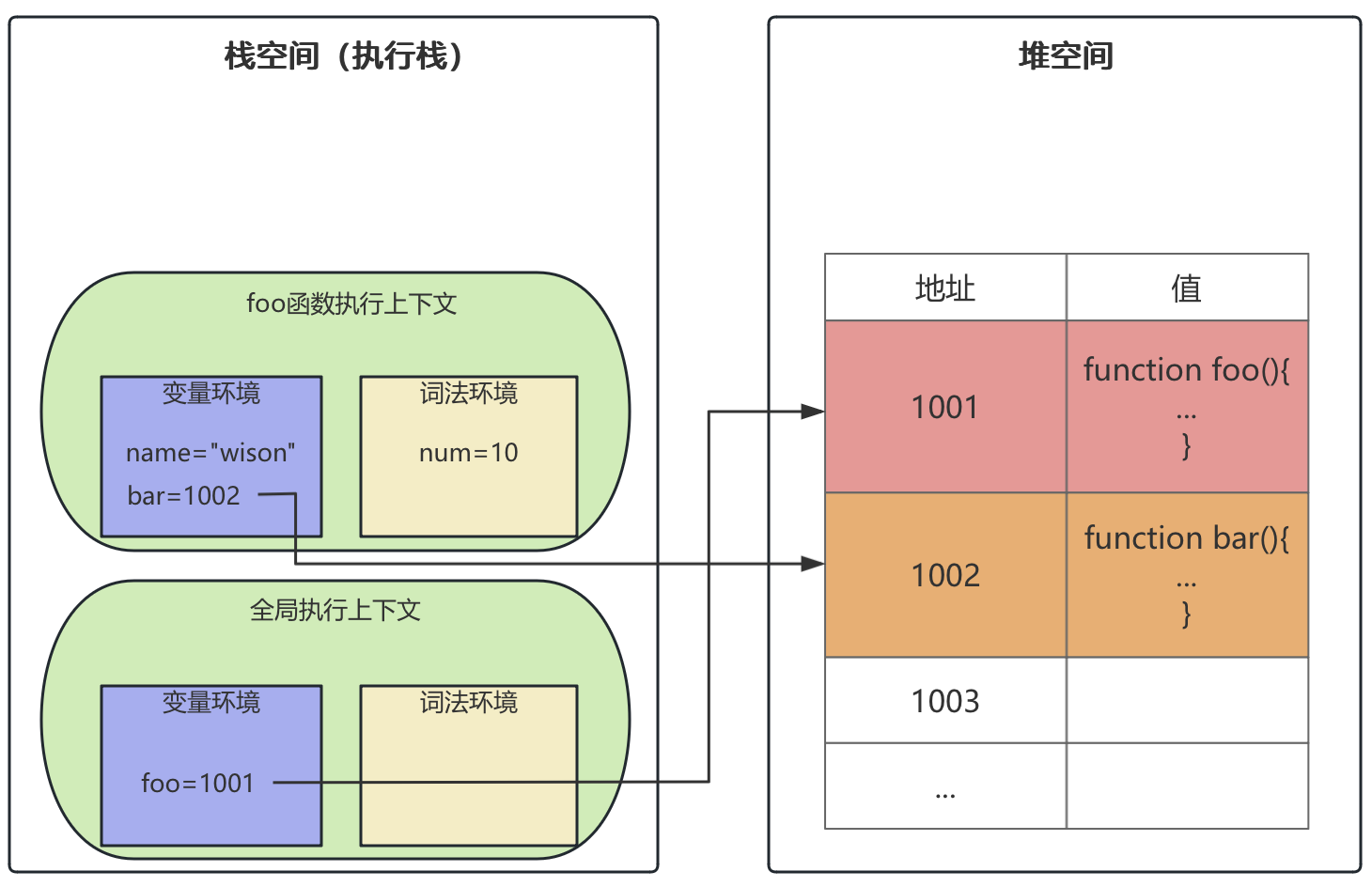
数据存储
在js运行的过程中,数据是怎么存储的?执行过程会有3种内存空间:代码空间、栈空间、堆空间,代码空间是存储可执行代码的。
上文说的执行栈就是栈空间,主要用来存储上下文。堆空间主要用来存储引用类型的数据。
function foo(){
var name = "wison"
let num = 10
function bar(){
console.log(num)
}
bar()
}
foo()
闭包产生的条件
- 函数嵌套
- 内部函数引用了外部函数的数据(变量/函数)
- 外部函数执行
function foo(){
var name = "wison"
let num = 10
function bar(){
console.log(num)
}
console.dir(bar)
}
foo()
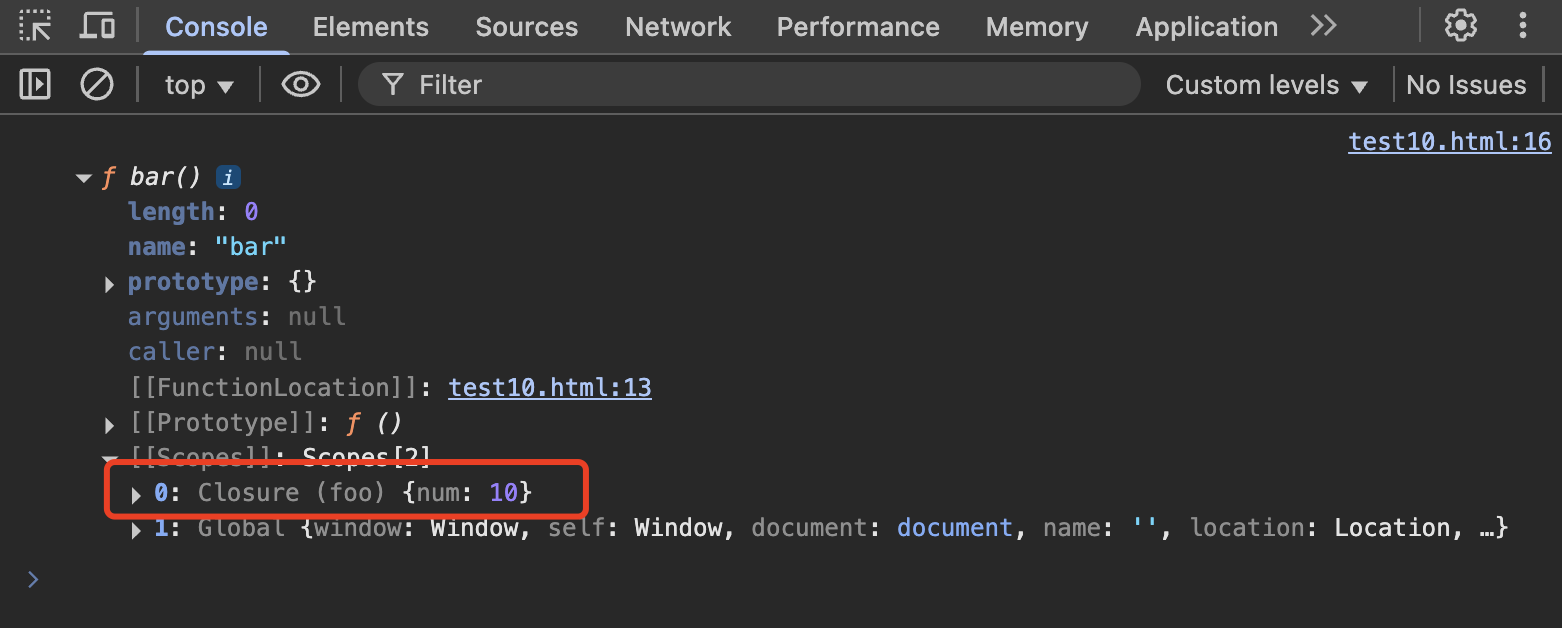
这时打印可以看到函数bar的[[scopes]]就记录outer指针的指向层级,里面有一个Closure就记录了闭包数据,就是当bar函数内访问不到变量,会先跟随outer指针访问Closure闭包里的变量数据,还找不到再指向window全局查找。
闭包作用
function foo(){
var name = "wison"
let num = 10
return function bar(){
console.log(num)
}
}
const bar = foo()
bar()
执行上面代码,你是否会奇怪,foo函数指向完毕对应的执行上下文会弹出执行栈,那么bar函数执行怎么还能访问到foo函数内容的变量呢?
因为bar函数在声明处访问了外部函数的变量,那么会生成一个Closure闭包,存放到堆内容中;且outer指针会先指向这个闭包;可以参考上面的[[scopes]]逻辑;堆内存会常驻而不会被垃圾回收。所以要注意内嵌函数会导致内存溢出的问题。
为什么会有闭包
有没有想过,为什么会有闭包这种设计呢?
隐约觉得这可能不是特意设计为之,想一想,其实全局代码可以看成一个main函数,那么它的子函数对全局变量引用时,就都会生成对应闭包,
但试下打印结果又不对。那会不会全局执行上下文就是一个大闭包?或者说每一个指向上下文都有一块闭包区域?